MusicLM - AI Music Generation from Text
MusicLM is a cutting-edge AI model that generates high-fidelity music from text descriptions. Developed by Google Research, it uses a hierarchical sequence-to-sequence modeling task to produce music at 24 kHz that remains consistent over several minutes.
Visit Website
https://google-research.github.io/seanet/musiclm/examples/?utm_source=perchance-ai.net&utm_medium=referral
Product Information
Key Features of MusicLM - AI Music Generation from Text
MusicLM generates high-fidelity music from text descriptions, using a hierarchical sequence-to-sequence modeling task, and supports conditioning on both text and melody.
Text-to-Music Generation
Generate high-fidelity music from text descriptions, such as 'a calming violin melody backed by a distorted guitar riff'.
Melody Conditioning
Condition MusicLM on both text and a melody, transforming whistled and hummed melodies according to the style described in a text caption.
Hierarchical Sequence-to-Sequence Modeling
Use a hierarchical sequence-to-sequence modeling task to generate music at 24 kHz that remains consistent over several minutes.
MusicCaps Dataset
Access the MusicCaps dataset, composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
Diversity in Generation
Test the diversity of the generated samples while keeping constant the conditioning and/or the semantic tokens.
Use Cases of MusicLM - AI Music Generation from Text
Generate music for film and video game soundtracks.
Create music for advertisements and commercials.
Produce music for live performances and concerts.
Use MusicLM for music education and composition.
Pros and Cons of MusicLM - AI Music Generation from Text
Pros
- Generates high-fidelity music from text descriptions.
- Supports conditioning on both text and melody.
- Uses a hierarchical sequence-to-sequence modeling task.
- Access to the MusicCaps dataset.
Cons
- May require significant computational resources.
- Limited to generating music in specific styles and genres.
- May not always produce coherent or meaningful music.
How to Use MusicLM - AI Music Generation from Text
- 1
Provide a text description of the desired music.
- 2
Condition MusicLM on a melody, if desired.
- 3
Adjust the model parameters to fine-tune the generation process.
- 4
Evaluate the generated music and refine the process as needed.
MusicLM - AI Music Generation from Text
Latest Free AI Tools Similar to MusicLM - AI Music Generation from Text
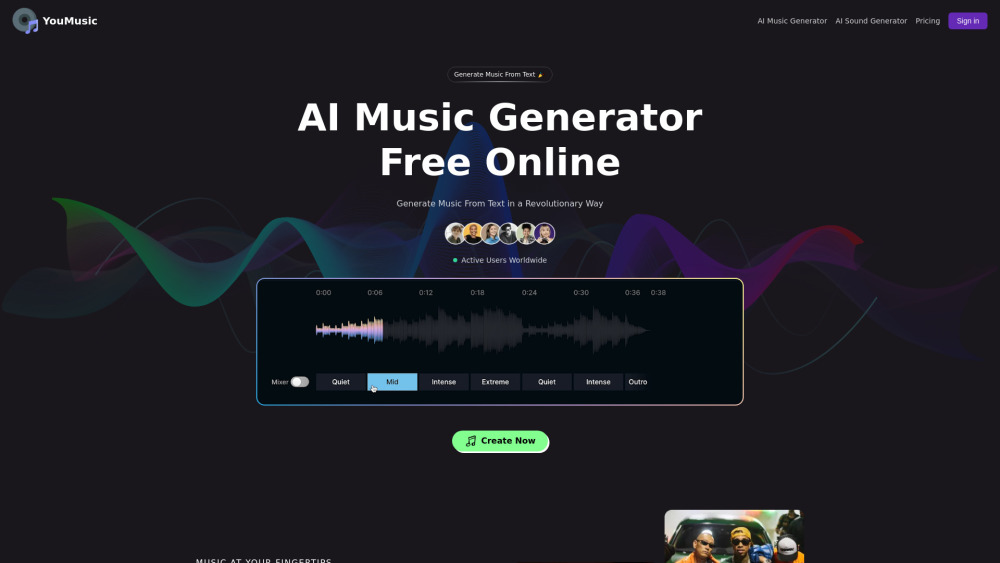
Generate music from text with the AI music generator on youmusic.ai. Create unique songs in just a few clicks and make unlimited royalty-free music for your projects and videos.

Rift Podcast transforms web content into personalized audio podcasts, offering unique insights on tech trends and innovations.
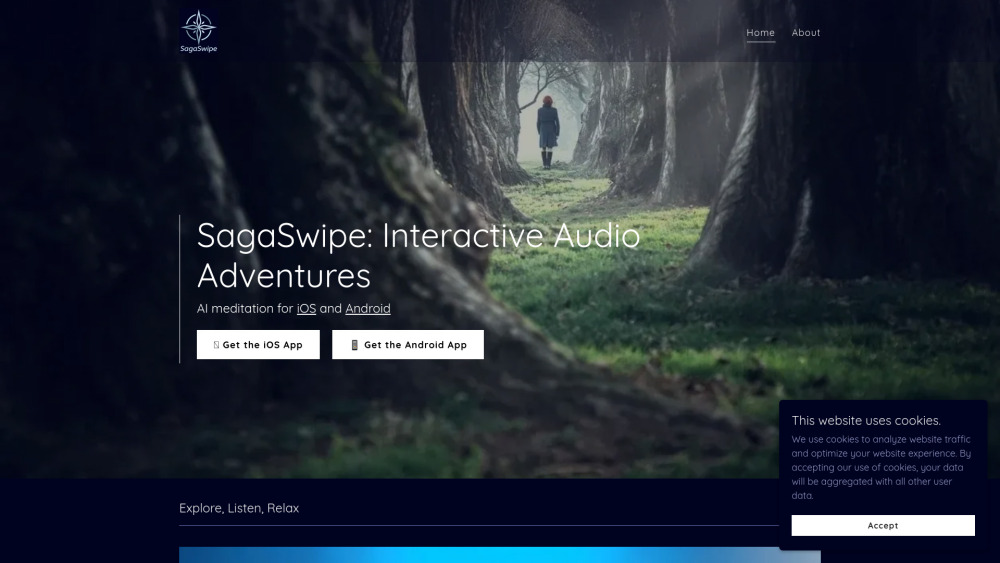
SagaSwipe offers an immersive escape into unique audio worlds, guided by your touch, to help you relax and tackle insomnia.
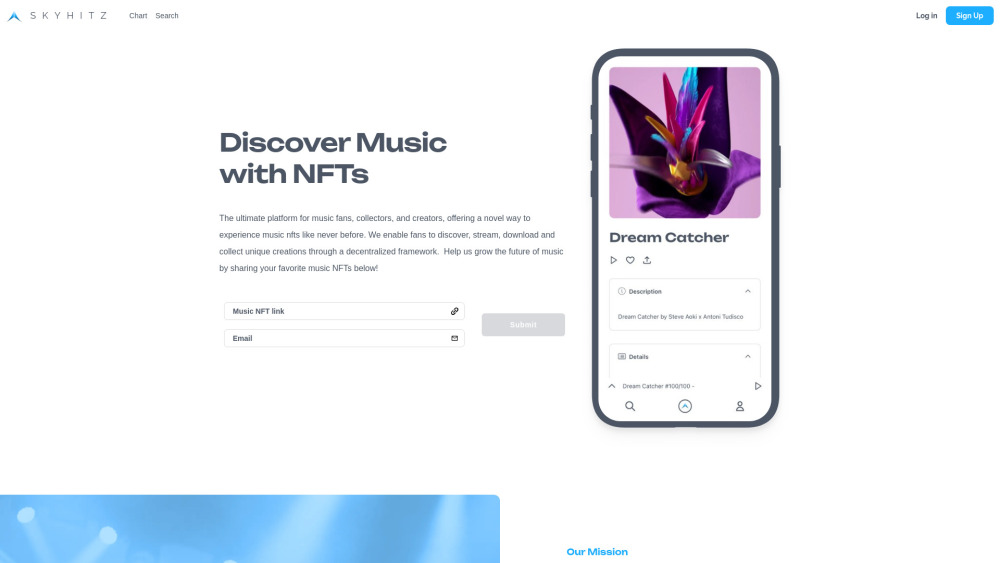
Skyhitz is a next-gen recording label that leverages smart contracts to empower creators with transparent monetization and provide music fans, collectors, and creators a groundbreaking way to discover, stream, and invest in unique tracks.
Popular Free AI Tools Similar to MusicLM - AI Music Generation from Text

Suno is an innovative AI-driven music creation platform that empowers users to produce high-quality original songs using text prompts, eliminating the need for musical skills or instruments.


UdioMusic AI is a cutting-edge online music generator that allows users to instantly create, customize, and download unique AI-generated music for free.
Birble AI is an innovative all-in-one AI-powered platform that integrates media creation, business tools, and Web3 development, leveraging over 30 AI models and blockchain integration for seamless experiences.