Helicone - LLM Observability for Developers
Helicone is an open-source platform for logging, monitoring, and debugging LLMs. It provides essential tools for developers to improve their LLMs, including request filtering, instant analytics, and prompt management.
Visit Website
https://www.helicone.ai/?utm_source=perchance-ai.net&utm_medium=referral
Product Information
Key Features of Helicone - LLM Observability for Developers
Helicone offers a range of features, including request filtering, instant analytics, prompt management, and 99.99% uptime. It also provides scalability and reliability, with sub-millisecond latency and risk-free experimentation.
Request Filtering
Filter, segment, and analyze your requests with Helicone's powerful filtering capabilities.
Instant Analytics
Get detailed metrics such as latency, cost, and time to first token with Helicone's instant analytics.
Prompt Management
Access features such as prompt versioning, prompt testing, and prompt templates with Helicone's prompt management.
99.99% Uptime
Helicone leverages Cloudflare Workers to maintain low latency and high reliability, ensuring 99.99% uptime.
Scalability and Reliability
Helicone is 100x more scalable than competitors, offering read and write abilities for millions of logs.
Use Cases of Helicone - LLM Observability for Developers
Improve your LLM's performance with Helicone's request filtering and instant analytics.
Use Helicone's prompt management to access features such as prompt versioning and prompt testing.
Deploy Helicone on-prem for maximum security and scalability.
Use Helicone's open-source platform to contribute to the community and improve the platform.
Pros and Cons of Helicone - LLM Observability for Developers
Pros
- Helicone is open-source and values transparency and community involvement.
- Helicone provides essential tools for developers to improve their LLMs.
- Helicone offers scalability and reliability, with sub-millisecond latency and risk-free experimentation.
Cons
- Helicone may have a learning curve for developers who are new to LLMs and observability platforms.
- Helicone may require additional setup and configuration for on-prem deployment.
How to Use Helicone - LLM Observability for Developers
- 1
Sign up for a demo to try Helicone's features and see how it can improve your LLM.
- 2
Deploy Helicone on-prem for maximum security and scalability.
- 3
Contribute to the Helicone community by joining the Discord channel and submitting issues on GitHub.
- 4
Use Helicone's open-source platform to improve your LLM's performance and reliability.
Helicone - LLM Observability for Developers
Latest Free AI Tools Similar to Helicone - LLM Observability for Developers

Experience the power of AI without restrictions with Uncensored AI, the #1 AI platform that provides unfiltered and unbiased responses.
ChatGPT Dansk er en AI-drevet chatbot, der hjælper dig med en lang række opgaver, lige fra at besvare spørgsmål og give information til at hjælpe med kreativ skrivning, problemløsning og meget mere.

Chat100.ai offers free AI chat with GPT4o and Claude 3.5 Sonnet for real-time, accurate answers. Access advanced ChatGPT features and experience the best ChatGPT alternative, all without login or fees.
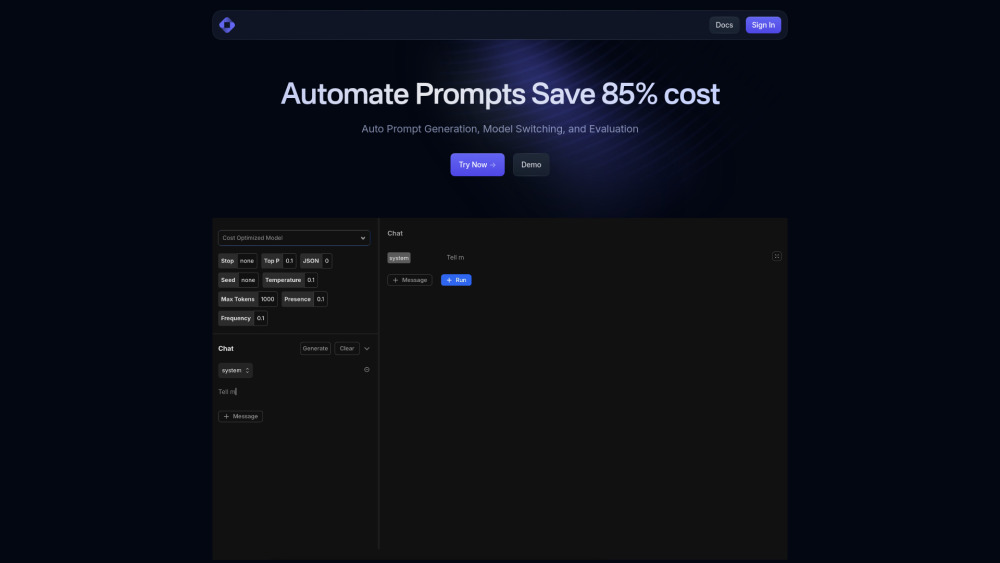
Trainkore is an AI platform that automates prompt generation, model switching, and evaluation, helping users save up to 85% of costs. With its advanced controls, observability suite, and iterative logs, Trainkore enables users to build good AI by understanding their users and creating effective prompts.
Popular Free AI Tools Similar to Helicone - LLM Observability for Developers

KaneAI empowers users to create, debug, and evolve software tests using intuitive natural language inputs, pioneering a new era in end-to-end AI-powered testing.

Jynnt is a versatile AI platform that empowers users to leverage the capabilities of over 100 AI models through a lightweight and efficient interface, complete with unlimited usage.

GPT-4o Mini is a simplified version of the GPT-4o model, offering efficient language processing capabilities, improved response times, and reduced resource requirements.

Meta Llama 3.1 is an open-source large language model available in three versions - 8B, 70B, and 405B - offering unprecedented flexibility in fine-tuning, distillation, and deployment.